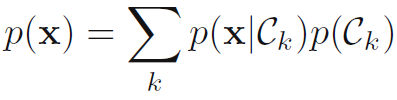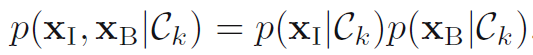DeepLearning/Pattern recognition and Machine learning
[PRML] 1.5.4 Inference and decision (추론과 결정)
TTSR2024. 1. 11. 13:04
728x90
반응형
1. 개요
우리는 분류 문제를 두 단계로 나누어서 살펴봤다. 첫 번째는 추론 단계 (inference stage)로 p(Ck|x)에 대해 모델이 훈련데이터로 학습하는 단계이다. 그 다음은 결정 단계 (decision stage)로 최적의 클래스 배정을 위해 사후확률 (posterior probability)를 사용한다. 이와는 다른 방식으로 두 가지 문제를 동시에 다룰 수 있을 것이며 이는 어떤 함수를 통해 입력 x를 결정 선택들 (decisions)에 바로 지정하는 것이다. (a function that maps inputs x directly into decisions)
이러한 함수를 판별 함수 (discriminant function)이라 한다.
2. 내용
결정 문제들을 해결하기 위해 우리는 3가지 구분되는 방법들이 있으며 이것들 모두 실용적으로 활용된다. 복잡한 정도가 낮아지는 순으로 소개하면 아래와 같다.
각 클래스 Ck에 대해 클래스-조건부 밀도 (class-conditional densities) p(x|Ck)를 결정하는 문제를 독립적으로 푼다. 또한, 사전 클래스 확률들 (prior class probabilities) p(Ck)를 추론한다. 그후 베이즈 정리를 수식 1.82의 형태로 사용하여 사후확률 p(Ck|x)를 찾는다. 수식 1.82
수식 1.83과 같이 베이즈 정리의 분모는 분자에 나타난 양들을 이용하여 찾을 수 있습니다. 수식 1.83
이와같은 방식으로, 결합확률 p(x,Ck)를 모델링할 수 있으며 표준화 (normalize)하여서 사후확률을 얻을 수 있습니다. 사후 확률을 찾은 후에는 의사 결정 이론을 사용하여 각 새로운 입력 x에 대한 클래스 소속을 결정합니다. 입력 및 출력의 분포를 명시적으로 또는 암묵적으로 모델링하는 방법은 생성 모델이라고 알려져 있습니다. 이 모델들은 그것 (입력값의 학습된분포) 들로부터 샘플링함으로써 입력 공간에서 합성 데이터 포인트를 생성하는 것이 가능하기 때문에 생성 모델 (generative models)이라고 불립니다.
먼저, 클래스 사후확률 p(Ck|x)를 결정하는 추론 문제를 풀고나서, 클래스들 중 하나에 새로운 x를 지정하는 결정이론을 사용하는 것이 있다. 사후확률을 모델링하는 접근방식을 판별 모델 (discriminative models)라고 한다.
입력값 x를 직접 클래스에 지정 (map)하는 함수 f(x)를 찾는 것이다. 이러한 함수를 판별 기능 (discriminant function)이라 한다. 예를들어, 2가지 클래스 문제들의 경우 f(*)는 f=0은 C1을 의미하고 f=1은 C2를 의미하는 이진값 (binary valued)일 수 있다. 이러한 경우 확률은 어떠한 역할도 하지 않는다.
1번 방식은 입력 x와 클래스 Ck에 대한 결합분포 (joint distribution)을 찾아야하기 때문에 가장 어렵다. 많은 상황들에서, x는 고차원이고 이 때문에 괜찮은 정확도를 얻기 위해서는 클래스-조건부 밀도를 결정하는데에는 거대한 훈련 데이터가 필요하다. 여기서, 클래스 사전확률 p(Ck)는 간단히 훈련 데이터셋의 각 클래스의 비율에서 예측될 수 있다. 1번 방식의 장점은 데이터의 주변 밀도 (marginal density of data) p(x)를 결정할 수 있다는 것입니다. 이는 모델에 대해 확률이 낮은 새로운 데이터 포인트를 감지하고 해당 예측이 낮은 정확도를 가질 수 있는 경우에 유용할 수 있습니다. 이는 이상치 감지 (outlier detection) 또는 신규성 감지 (novelty detection)로 알려져 있다.
하지만, 우리가 오로지 분류 결정만을 하고 싶다면 결합 분포 p(x,Ck)를 찾는 것은 컴퓨터 자원 낭비이며 데이터를 많이 요구한다. 이 경우에는 사후확률 p(Ck|x)만 필요하고 이것은 2번 방식을 통해 바로 얻을 수 있다. 실제로, 그림 1.27에 묘사된 것과 같이 클래스-조건부 분포 (class-conditional densities)는 사후확률에 대해 미미한 효과를 갖는 다양한 구조가 있을 수 있다.
그림 1.27. 왼쪽 : 사전확률, 오른쪽 : 사후확률
보다 쉬운 접근법은 3번 방식으로 훈련데이터를 이용하여 판별 함수 f(x)를 찾아서 x를 직접 클래스 라벨에 지정하는 것이다. 이를 통해 추론과 결정단계를 하나의 학습 문제로 통합할 수 있다. 그림 1.27의 예에서는 초록색 수직선을 찾는 것에 상응할 것이다. 왜냐하면 이것이 분류 오차를 최소화시키는 결정 경계이기 때문이다. 하지만, 3번 방식의 문제는 사후확률 p(Ck|x)에 접근할 수 없게 된다는 것이다.
사후확률을 계산하는데에는 많은 이유가 있다.
위험 최소화 (Minimizing risk) 금융 상황과 같이 손실 행렬 (loss matrix)의 원소들이 시간에 따라 바뀌는 문제가 있다고 가정해보자. 만일 우리가 사후 확률을 안다면, 수식 1.81을 적절히 개조하여 최소 위험 결정 기준을 쉽게 조정할 수 있을 것이다. 만일 우리가 판별 함수만이 가능하다면, 손실 행렬에서 일어나는 모든 변화는 분류 문제를 풀기위해 훈련 데이터에서부터 다시 시작하게 만들 것이다.
거부 선택 (Rejct option) 사후 확률은 잘못된 분류율을 낮추는 거부 기준치를 정하는데 도움이 된다.
클래스 사전확률에 대한 보충/보완 (Compensating for class priors) 암환자 분류 문제를 이야기해보겠다. 암은 전체 인구에서는 희귀하므로 1000 개의 샘플 당 1개 비율로 암이 존재한다고 가정해보겠다. 우리가 어떤 모델을 해당 데이터셋으로 만들면 암 환자 비율이 적기 때문에 매우 심각한 어려움을 직면하게 된다. 예를들어 어떤 분류자가 모든 데이터 포인트를 정상이라고 지정하더라도 이것의 정확도는 99.9%에 도달한다. 또한, 매우큰 데이터셋에서도 암 환자에 상응하는 x-ray 이미지는 적고 학습 모델은 넓은 범위의 훈련데이터를 접하지 못해서 일반화가 잘 안될 가능성이 있다. 클래스 라벨이 균형 잡히게 만든 데이터셋은 보다 정확한 모델을 개발하는데 도움이 될 수 있다. 하지만, 훈련데이터를 개조함에 따라 생긴 효과를 보완해야한다. 우리가 개조한 훈련데이터를 통해 사후확률에 대한 모델링을 했다고 가정하자. 베이즈 정리 (수식 1.82)에 따라, 사후확률은 사전확률에 비례한다. 여기서 사전확률은 각 클래스의 비율로 해석할 수 있다. 따라서, 우리는 간단히 인위적으로 균형잡힌 데이터셋으로부터 사후확률을 얻을 수 있고 해당 데이터셋에서 클래스 비율을 나눈 후 전체 인구에서의 클래스 비율로 곱해줘서 조정할 수 있다. 마지막으로 새로운 사후확률의 합이 1이 되도록 표준화해주면 된다. 이러한 과정은 우리가 판별 기능을 사용한다면 적용할 수 없는 절차이다.
모델 결합 (Combining models) 복잡한 상황들에 대해, 분리된 모듈을 활용하여 작은 문제들로 쪼갠 후에 풀고 싶을 수도 있다. 예를들어, 우리가 x-ray 이미지 뿐만 아니라 혈액 검사 결과도 있을 수도 있다. 이러한 비균질한 데이터를 한 가지 공간에 모두 집어넣는 것보다는 x-ray 이미지 분류 모델과 혈액검사 판단 모델을 나누는 것이 좀 더 효과적일 수 있다. 두 개의 모델이 각 클래스에 대한 사후확률을 제공하므로 우리는 확률 규칙을 활용해 체계적으로 통합할 수 있다. 한가지 간단한 방법은 각 x-ray 이미지 (xi)와 혈액 데이터 (xb)가 독립이라고 가정하면 수식 1.84와 같이 나타낼 수 있다. 수식 1.84
이것은 조건부 독립 특징 (conditional independence property)의 한가지 예이다. 클래스 Ck에 조건을 걸 때 독립성이 유지되기 때문이다. 사후확률은 주어진 X-ray와 혈액 데이터에의해 수식 1.85와 같은 특징이 있다. 수식 1.85
따라서, 우리는 사전확률 p(Ck)가 필요하다. 이것은 각 클래스의 데이터 포인트의 비율로부터 쉽게 구할 수 있다. 그리고 사후확률을 표준화 (normalize)하여 합이 1이 되도록 하면된다. 이 특별한 조건부 독립 가정 (수식 1.84)는 나이브 베이즈 (naive Bayes) 모델의 한 예이다. 여기서 결합 주변 분포 p(xi,xb)는 이 모델에서는 고려되지 않는다. 우리는 이후 챕터에서 조건부 독립 가정을 요구하지 않는 모델을 어떻게 만드는지 다룰 것이다.